We wpisie pod tytułem „Solr: tworzenie własnego filtra” pokazaliśmy implementację bardzo prostego filtra i jak użyć go w Apache Solr. Ostatnio, jeden z czytelników, poprosił nas o rozbudowanie tego tematu i opisanie jak można zwracać więcej, niż jeden term. Postanowiliśmy więc napisać kolejny wpis, który jest rozwinięciem poprzedniego.
Założenia
Załóżmy, że chcemy, aby nasz filtr nie tylko zapisywał do strumienia tokenów odwrócone słowo, ale także zachowywał oryginalne. Zatem ze słowa moje w strumieniu tokenów powinny pojawić się słowa moje oraz ejom. W tym celu zmodyfikujemy wcześniej stworzony filtr.
W tym wpisie pomijamy także wszelkie aspekty konfiguracji i poinformowania Solr o tym, gdzie szukać naszej biblioteki. Jeżeli tematy te nie są znane prosimy o przeczytanie poprzedniego wpisu.
Użyta wersja Solr
W odróżnieniu od poprzedniego wpisu opartego o Solr 3.6, tym razem zdecydowaliśmy się wykorzystać najnowszą, dostępną wersję tego silnika wyszukiwania. W związku z tym implementacja oparta jest o Solr w wersji 4.1. Aby filtr działał w Solr 3.6, wystarczy skorzystać z fabryki przedstawionej w poprzednim wpisie.
Fabryka
Jedyną różnicą w przypadku fabryki jest tylko i wyłącznie klasa jaką rozszerza. W tym wypadku jest to TokenFilterFactory z pakietu org.apache.lucene.analysis.util:
public class ReverseFilterFactory extends TokenFilterFactory {
@Override
public TokenStream create(TokenStream ts) {
return new ReverseFilter(ts);
}
}
Filtr
Sam filtr został mocniej zmodyfikowany i wygląda następująco:
public final class ReverseFilter extends TokenFilter {
private CharTermAttribute charTermAttr;
private PositionIncrementAttribute posIncAttr;
private Queue<char[]> terms;
protected ReverseFilter(TokenStream ts) {
super(ts);
this.charTermAttr = addAttribute(CharTermAttribute.class);
this.posIncAttr = addAttribute(PositionIncrementAttribute.class);
this.terms = new LinkedList<char[]>();
}
@Override
public boolean incrementToken() throws IOException {
if (!terms.isEmpty()) {
char[] buffer = terms.poll();
charTermAttr.setEmpty();
charTermAttr.copyBuffer(buffer, 0, buffer.length);
posIncAttr.setPositionIncrement(1);
return true;
}
if (!input.incrementToken()) {
return false;
} else {
// we reverse the token
int length = charTermAttr.length();
char[] buffer = charTermAttr.buffer();
char[] newBuffer = new char[length];
for (int i = 0; i < length; i++) {
newBuffer[i] = buffer[length - 1 - i];
}
// we place the new buffer in the terms list
terms.add(newBuffer);
// we return true and leave the original token unchanged
return true;
}
}
}
Kilka słów wyjaśnienia
Omówmy zatem różnice przedstawionej implementacji w stosunku do pierwotnej wersji filtra:
- Linia 4 – lista, która będzie nam służyć do przechowywania tokenów.
- Linia 9 – dodanie atrybutu odpowiedzialnego za przechowywanie pozycji tokena w strumieniu tokenów.
- Linia 10 – inicjalizacja listy zadeklarowanej w linii 4.
- Linie 15 – 21 – warunek, który sprawdza, czy na liście są obecne tokeny, które trzeba zapisać do strumienia. Jeżeli są pobiera pierwszy token z listy (usuwając go), ustawia atrybut odpowiedzialny za treść terma, ustawia atrybut odpowiedzialny za pozycję terma i zwraca wartość true, aby poinformować, że przetwarzanie powinno być kontynuowane. Warto zauważyć, iż ze strumienia nie został pobrany żaden token – nie było wywołania input.incrementToken().
- Linie 23 – 25 – sprawdzenie, czy w strumieniu został jakiś token. Jeżeli nie, to zwracamy wartość false i kończymy przetwarzanie.
- Linie 27 – 36 – odwrócenie tokena i zapisanie go do listy zadeklarowanej w linii 4. Nie modyfikując tokena, który aktualnie znajduje się w strumieniu i który odwróciliśmy zwracamy wartość true i tym samym informujemy Solr, że przetwarzanie należy kontynuować, a zatem Solr wywoła metodę incrementToken() naszego filtra po raz kolejny i po tym wywołaniu zostanie wywołany kod z linii 15 – 21 ze względu na to, że w liście terms znajduje się token dodany tam w linii 34.
Warto zwrócić uwagę na atrybut umożliwiający nam ustawianie pozycji w strumieniu tokenów. W przypadku powyższej implementacji, każdy odwrócony token, będzie zapisany na następnej pozycji w strumieniu w stosunku do oryginalnego tokena. Tłumacząc najprościej oznacza to, iż tokeny te będą traktowane jako oddzielne słowa. Za chwilę sprawdzimy co się stanie, jeżeli umieścimy odwrócony token na tej samej pozycji co oryginalny.
Działanie
Działanie powyższego filtra postanowiliśmy zilustrować korzystając z panelu administracyjnego Solr:
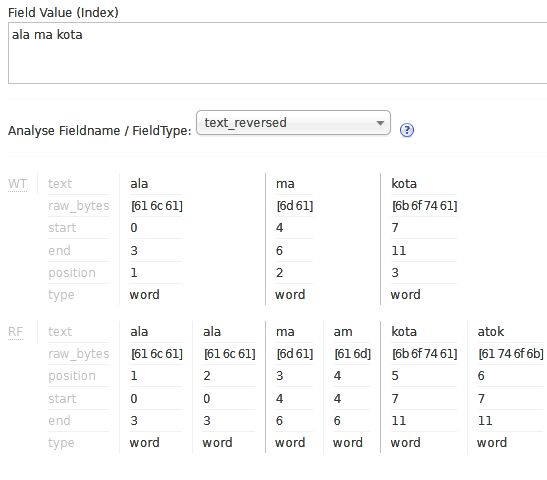
Jak widać, zostały zapisane zarówno oryginalne wartości ala, ma oraz kota, a także ich odwrotności, czyli ala, am i atok. Dodatkowo warto zauważyć, iż każdy z tokenów został zapisany na innej, kolejnej pozycji (atrybut position). A zatem wszystko zadziałało tak jak należy.
Zmiana atrybutu odpowiedzialnego za pozycję w strumieniu
Sprawdźmy jak zmieni się działanie filtra kiedy zmienimy linię:
posIncAttr.setPositionIncrement(1);
na
posIncAttr.setPositionIncrement(0);
Działanie
 Po zmianie oryginalny token i jego odwrócona wersja zostały umieszczone na tej samej pozycji, co jest dokładnie tym co chcieliśmy osiągnąć. Tym samym będziemy np. w stanie zadać zapytanie w stylu q=”ala am kota”, czyli wymienić oryginalny token na jego odwróconą wersję w przypadku zapytań o frazę.
Po zmianie oryginalny token i jego odwrócona wersja zostały umieszczone na tej samej pozycji, co jest dokładnie tym co chcieliśmy osiągnąć. Tym samym będziemy np. w stanie zadać zapytanie w stylu q=”ala am kota”, czyli wymienić oryginalny token na jego odwróconą wersję w przypadku zapytań o frazę.
Kilka słów na koniec
Jak widać tworzenie własnych filtrów nie jest trudne, przynajmniej jeżeli chodzi o warstwę Lucene/Solr. Dostajemy do rąk dość duże możliwości, jeżeli chodzi o kontrolę tego, co finalnie znajdzie się w strumieniu tokenów m.in. dzięki atrybutom strumienia. Oczywiście skomplikowanie danego filtra zależy od logiki, jaką chcemy zaimplementować, jednak nie jest to tematem tego wpisu 🙂