In the previous entry “Developing Your Own Solr Filter” we’ve shown how to implement a simple filter and how to use it in Apache Solr. Recently, one of our readers asked if we can extend the topic and show how to write more than a single token into the token stream. We decided to go for it and extend the previous blog entry about filter implementation.
Assumptions
Let’s assume that we want not only to return the reversed word, but also to keep the original one. So if we would pass the fine word to the analysis we would like to have fine and enif returned. In order to achieve that we will modify the filter created in the previous entry.
We will omit all the details of the configuration and installation, so if you would like to read about them please refer to the previous post.
Solr version
We would also like to note that in this post we’ve decided to go for the newest available Solr version, so we’ve used the 4.1. In order to have the following filter working on 3.6 just used the filter factory shown in the previous entry.
Filter factory
The only difference when it comes to the filter factory is the class we are extending. Because we are using Solr 4.1, we extend the TokenFilterFactory from the org.apache.lucene.analysis.util package:
public class ReverseFilterFactory extends TokenFilterFactory {
@Override
public TokenStream create(TokenStream ts) {
return new ReverseFilter(ts);
}
}
Filter
The filter was modified a bit more and looks like this:
public final class ReverseFilter extends TokenFilter {
private CharTermAttribute charTermAttr;
private PositionIncrementAttribute posIncAttr;
private Queue<char[]> terms;
protected ReverseFilter(TokenStream ts) {
super(ts);
this.charTermAttr = addAttribute(CharTermAttribute.class);
this.posIncAttr = addAttribute(PositionIncrementAttribute.class);
this.terms = new LinkedList<char[]>();
}
@Override
public boolean incrementToken() throws IOException {
if (!terms.isEmpty()) {
char[] buffer = terms.poll();
charTermAttr.setEmpty();
charTermAttr.copyBuffer(buffer, 0, buffer.length);
posIncAttr.setPositionIncrement(1);
return true;
}
if (!input.incrementToken()) {
return false;
} else {
// we reverse the token
int length = charTermAttr.length();
char[] buffer = charTermAttr.buffer();
char[] newBuffer = new char[length];
for (int i = 0; i < length; i++) {
newBuffer[i] = buffer[length - 1 - i];
}
// we place the new buffer in the terms list
terms.add(newBuffer);
// we return true and leave the original token unchanged
return true;
}
}
}
Implementation description
Let’s talk about the differences between the above filter and the version shown in the previous blog post:
- Line 4 – a list, that will be used to hold term buffer that needs to be written to token stream.
- Line 9 – we add the attribute that is responsible for setting the token position in the token stream.
- Line 10 – initialization of the list we’ve defined in line 4.
- Line 15 – 21 – condition that checks if we have tokens in the lists that we need to process. If there are such tokens we take the first token from the list (and we remove it), we set the term buffer, we set its position in the token stream abd we return true in order to inform that processing should be continued. It is worth noting that we didn’t fetch a new token from the token stream, because we didn’t call the input.incrementToken() method.
- Lines 23 – 25 – we check if there are tokens left for processing. If there are not we just return false and we end processing.
- Lines 27 – 36 – we reverse the token and we add it to the list declared on line 4. We didn’t modify the token that is actually present in the token and we return true. By doing this we inform Solr that we want to continue processing and Solr should call the incrementToken() method of our filter. After the next call we will end up executing the code from lines 15 – 21 because our list will contain a new token.
There is one more thing that is worth noting in our opinion – the position increment attribute. In the above implementation, each reversed token will be written in the next position in the token stream comparing to the original token. To put it simple – those tokens will be treated as single words. In a few we will check what will happen when the reversed tokens will be put on the same positions as the original ones.
Does it work ?
The work of the above filter can be illustrated by using Solr administration panel:
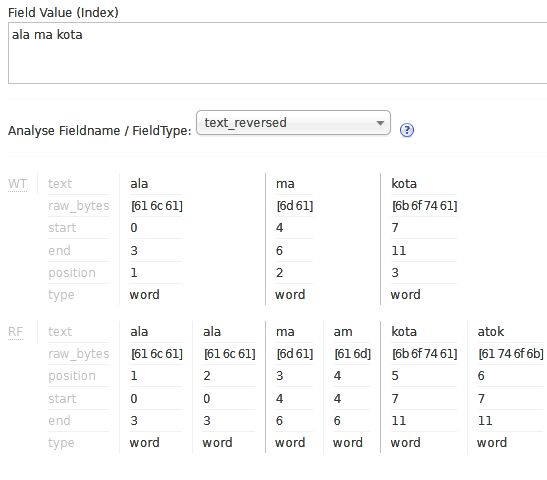
As you can see, both original values: ala, ma and kota and the reversed ones ala, am and atok were put on in a new positions (the position attribute). So it works as intended
Let’s change the position increment
So let’s check what will happen when we change the following line:
posIncAttr.setPositionIncrement(1);
to the following one:
posIncAttr.setPositionIncrement(0);
How it works
Again, let’s illustrate how it works by looking at Solr administration panel:
 As you can see, after the change, both original token as well as its reversed version were put on the same position, which is what we wanted to achieve. Because of that we can now run queries like q=”ala am kota” (look at the am word). What we gain is the ability to use original or reversed tokens in the phrase queries.
As you can see, after the change, both original token as well as its reversed version were put on the same position, which is what we wanted to achieve. Because of that we can now run queries like q=”ala am kota” (look at the am word). What we gain is the ability to use original or reversed tokens in the phrase queries.
To sum up
As you can see creating your own filters is not a rocket science, at least when it comes to Lucene and Solr part. What we get from Lucene and Solr is a nice set of features which we can use to control what will be finally put in the token stream, for example thanks to token stream attributes. Of course the complexity of the code will depend on you business logic, but this is far beyond the scope of this post 🙂